TVL
A Touch, Vision, and Language Dataset for Multimodal Alignment
TL;DR: Multi-modal alignment made easy using GPT-4V pseudolabels.
Overview
We introduce the Touch-Vision-Language (TVL) dataset, which combines paired tactile and visual observations with both human-annotated and VLM-generated tactile-semantic labels. We then leverage a contrastive learning approach to train a CLIP-aligned tactile encoder and finetune an open-source LLM for a tactile description task. Our results show that incorporating tactile information allows us to significantly outperform state-of-the-art VLMs (including the label generating model) on a tactile understanding task.
The TVL Dataset

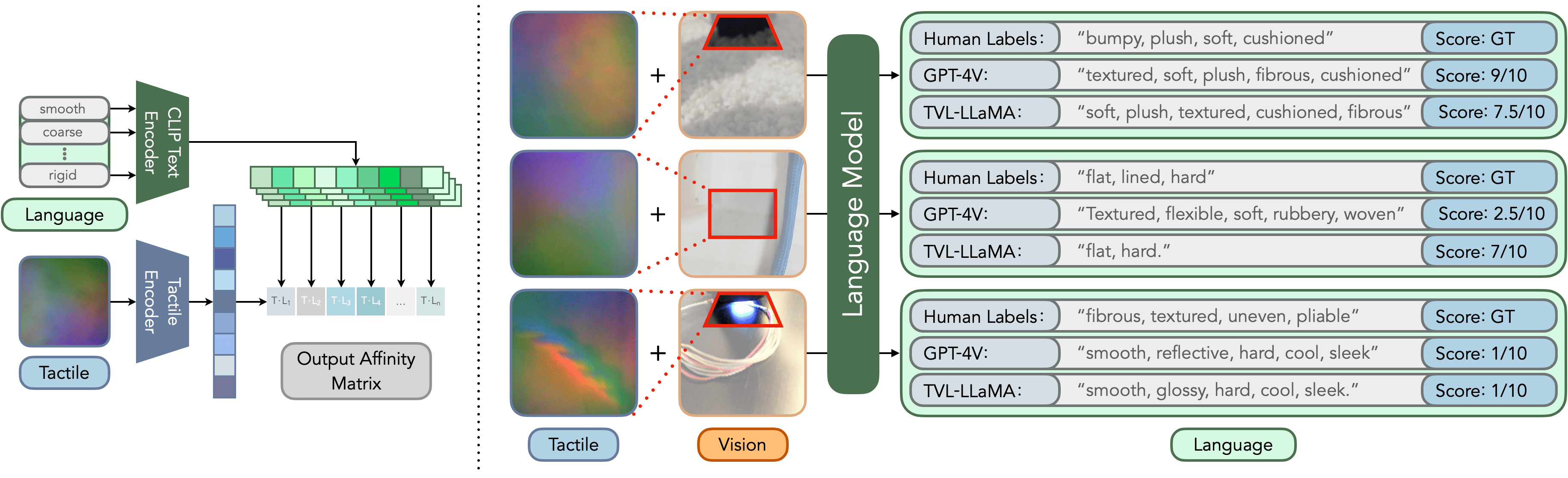
We gather data using a handheld, 3D printed collection device. Tactile data are collected using a DIGIT sensor: a compact, open-source tactile sensor that provides observations in the form of RGB images of a deformable internal surface. Image data come from a Logitech BRIO webcam, positioned such that the tactile sensor and the point of contact are within its field of view. The collected data are then temporally synchronized and labeled with language descriptions of the tactile sensations present to produce a dataset of aligned touch-vision-language examples.
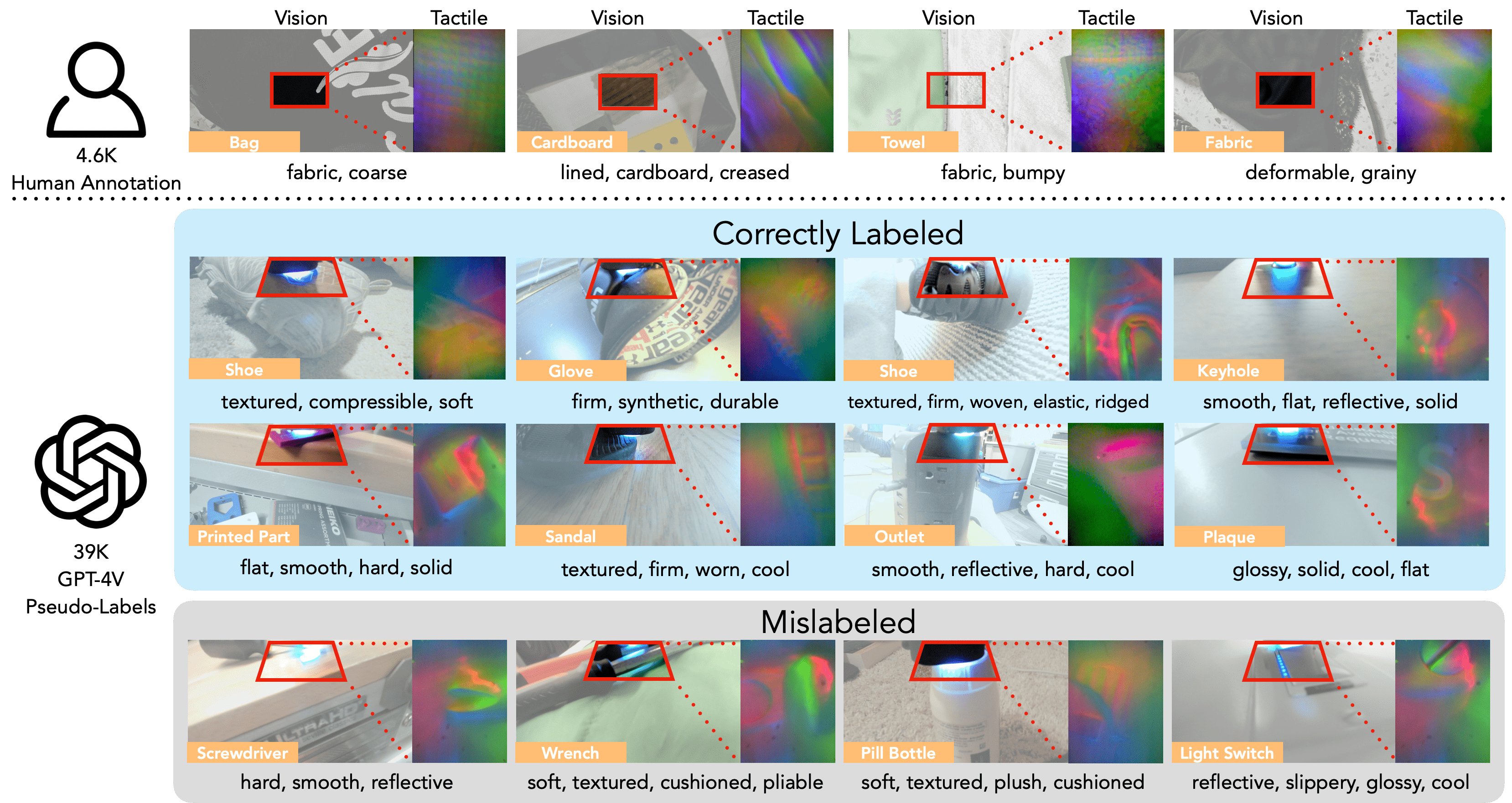
The TVL Dataset is then formed by combining two datasets: SSVTP (Kerr et al., 2023), a robot-collected dataset of 4,587 image-touch pairs, and HCT, our newly-collected dataset consisting of 39,154 synchronously captured in-the-wild image-touch pairs. For the SSVTP dataset, we manually append image labels to the data (some examples are shown in the first row). For the HCT portion of the dataset, we prompt GPT-4V to label the dataset based on the visual inputs. Note that while GPT-4V is a very efficient visual labeler, it does occasionally fail to provide correct tactile labels (examples shown in row 4), especially when the contact patch is occluded by the sensor or when there is not sufficient visual information to estimate the tactile sensation. In total, this results in a dataset containing 43,741 in-contact image-touch pairs with open-vocabulary language labels.
Model Architecture and Training
Encoder Alignment begins by randomly initializing the tactile encoder as a Vision Transformer (ViT). During training, we take as input the tactile image, and use the embeddings from the representations of the paired language and vision examples after going through the respective encoders. We remove the projectors from these two encoders such that the tactile encoder learns to directly project to the common CLIP latent space. We test on three model sizes: ViT-Tiny (5.7M paraeters), ViT-Small (22M), and ViT-Base (86M) and notice that directly adopting the ImageBind training recipe leads to overfitting on our relatively small training dataset of 44K pairs of in-contact data. Instead, we find that leveraging data in which the tactile sensor is not in contact with a surface (background images, which we collect as part of each trajectory) can mitigate this overfitting problem and enhance tactile representation learning by improving visual data diversity. Therefore, we also add an additional 10% of the training data where the sensor is not in contact and assign these examples a text label of “background”. To further increase the diversity of language labels, we also randomly shuffle and select a subset of the words in the tactile description for each image.
For the language generation task, we pretrain on both the LLaVA Visual Instruct CC3M 595K subset and the TVL dataset. For the CC3M subset, we provide an empty tactile image to the tactile modality. Then, during finetuning, we use a combination of TVL, Alpaca, and the LLaVA Visual Instruct 150K datasets. The tactile-semantic labels from the TVL dataset are further parsed and fed into a series of different Q&A prompts to increase data diversity.
Results
We measure the performance of our model on a tactile-semantic understanding task, as well as the alignment of our tactile encoder across different modes.
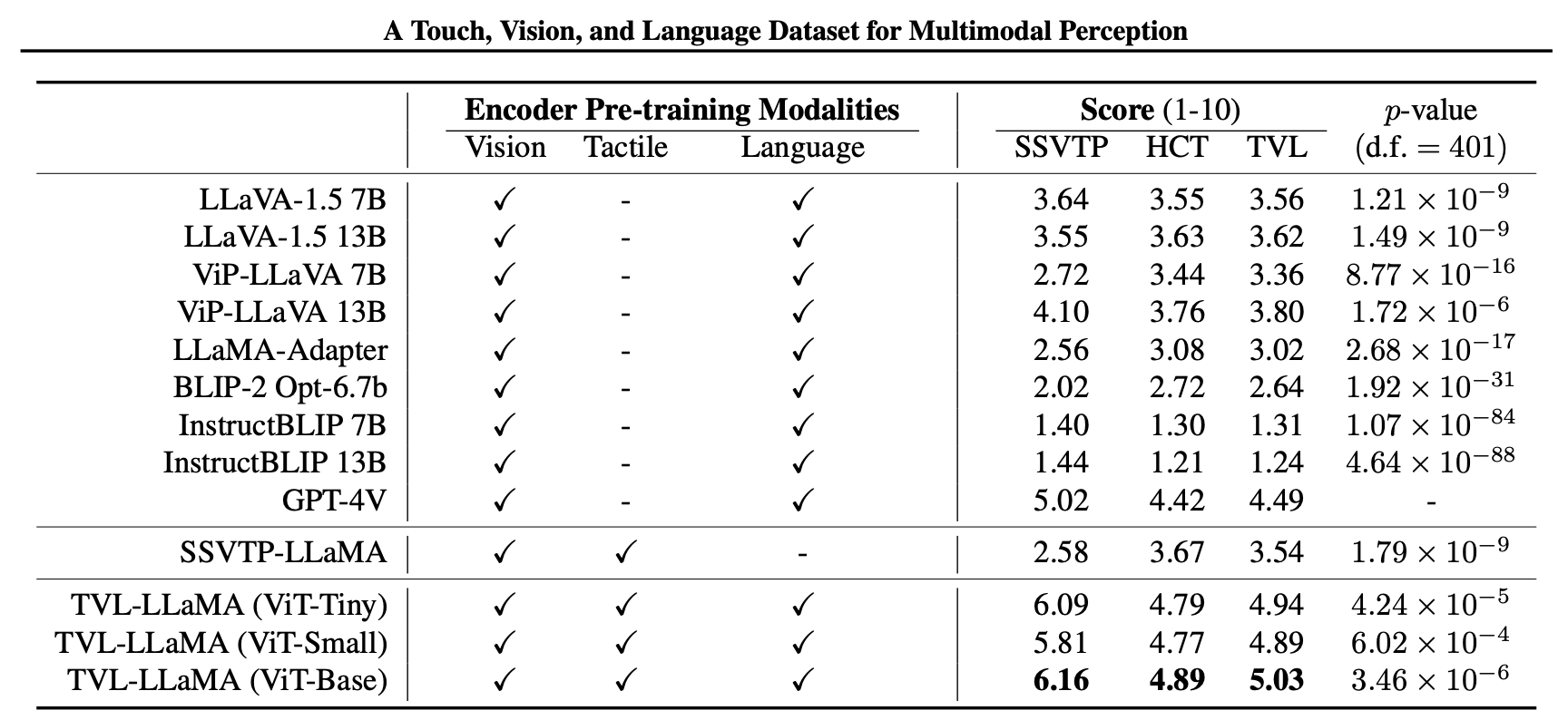
On our tactile-semantic classification task, we find all sizes of TVL-LLaMA outperform GPT-4V, suggesting that our trained models generalize beyond the small fraction of human labels provided as part of the dataset. On the other hand, other open-source VLMs perform worse than GPT-4V on our benchmark, likely due to the lack of attention to human tactility in their visual training data. Furthermore, our results also suggest that direct tactile-language alignment is useful, as evidenced by the lower comparative score of SSVTP-LLaMA, which only aligns the tactile and visual modalities during pre-training. All of these findings are statistically significant at the α = 0.05 level.
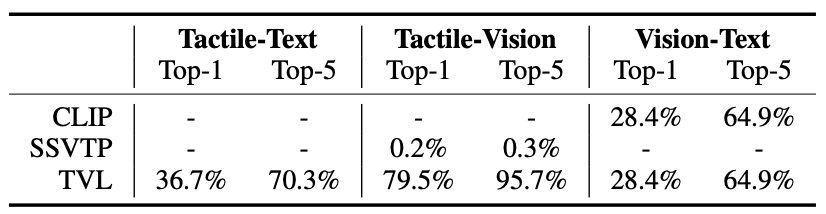
As we use OpenCLIP to encode image and language observations, the TVL encoder shares its vision-language accuracy scores with other OpenCLIP-based models. We therefore compare the tactile-vision accuracy of our encoder against SSVTP; because they train on a small dataset collected in a lab setting, their model performs well on the lab-collected subset of the data, but does not generalize well to the new “in-the-wild” portion of the dataset. Additionally, since the tactile encoder is aligned to the language descriptions of tactility, it also shows better tactile-text alignment than OpenCLIP’s vision-text alignment.

Citation
If you use this work or find it helpful, please consider citing our work.
@inproceedings{
fu2024a,
title={A Touch, Vision, and Language Dataset for Multimodal Alignment},
author={Letian Fu and Gaurav Datta and Huang Huang and William Chung-Ho Panitch and Jaimyn Drake and Joseph Ortiz and Mustafa Mukadam and Mike Lambeta and Roberto Calandra and Ken Goldberg},
booktitle={Forty-first International Conference on Machine Learning},
year={2024},
url={https://openreview.net/forum?id=tFEOOH9eH0}
}